Vorteile von Skalierung
Autor: Adrian Schweizer, Datum: 22. August 2022
Eine skalierbare IT Infrastruktur ist oft eines der Hauptziele bei einer Cloud-Transformation. In diesem Blog-Post sollen verschiedene Situationen aufgezeigt werden, in welchen eine skalierbare Infrastruktur von Vorteil sein kann. Zusätzlich wird jeweils noch erläutert, wie eine ausschliesslich auf Serverless-Diensten basierte Infrastruktur in der jeweiligen Situation abschneidet.
Tag/Nacht Zyklus
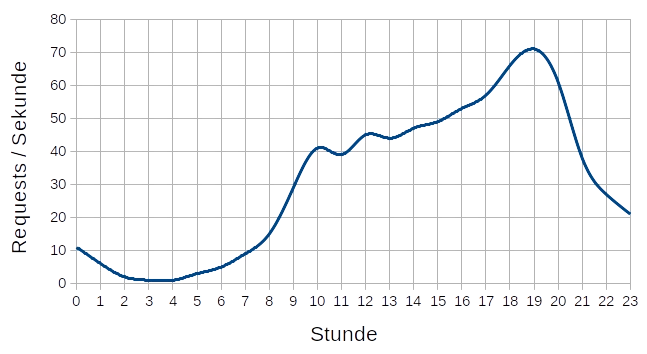 Viele lokale Webseiten zeigen eine tägliche Lastkurve auf, die eine grosse Spanne zwischen dem
Minimal- und dem Maximalwert aufweist. Oft läuft
in der Nacht fast gar nichts und am Abend zwischen 17 und 22 Uhr passieren fast die Hälfte aller
Zugriffe. Ein einzelner Webserver ist also entweder
während geraumer Zeit am Däumchen drehen oder kann dann in der Hauptphase des Betriebs nicht mehr
alle Anfragen bedienen. Da man die zweite Situation
natürlich möglichst vermeiden möchte, muss stets dafür gesorgt werden, dass die maximale Tageslast
abgedeckt ist. Man sieht leicht, dass im gezeigten
Diagramm ein Server, welcher die Maximallast abdecken könnte, mind. die Hälfte seiner Rechenleistung
nicht nutzen würde. Tatsächlich wäre dieser Wert noch höher,
da man natürlich nach oben noch etwas Luft einplanen sollte.
Viele lokale Webseiten zeigen eine tägliche Lastkurve auf, die eine grosse Spanne zwischen dem
Minimal- und dem Maximalwert aufweist. Oft läuft
in der Nacht fast gar nichts und am Abend zwischen 17 und 22 Uhr passieren fast die Hälfte aller
Zugriffe. Ein einzelner Webserver ist also entweder
während geraumer Zeit am Däumchen drehen oder kann dann in der Hauptphase des Betriebs nicht mehr
alle Anfragen bedienen. Da man die zweite Situation
natürlich möglichst vermeiden möchte, muss stets dafür gesorgt werden, dass die maximale Tageslast
abgedeckt ist. Man sieht leicht, dass im gezeigten
Diagramm ein Server, welcher die Maximallast abdecken könnte, mind. die Hälfte seiner Rechenleistung
nicht nutzen würde. Tatsächlich wäre dieser Wert noch höher,
da man natürlich nach oben noch etwas Luft einplanen sollte.
Um die tägliche Lastschwankung besser abzudecken, empfiehlt es sich, horizontale Skalierung (Anzahl Instanzen in der Flotte erhöhen) einzusetzen. Vertikale Skalierung (Grösse der Instanzen erhöhen) wäre theoretisch auf AWS auch möglich, empfiehlt sich hier aber nicht, da die Instanzgrösse immer um den Faktor 2 wächst oder schrumpft, und somit die Lastkurve nicht optimal abgedeckt werden kann.
Falls auf eine Serverless Architektur gesetzt wird, kann die Lastkurve noch granularer angenähert werden. Dies liegt daran, dass EC2 Instanzen auch für angebrochene Stunden den vollen Preis kosten, und es somit keinen Sinn macht, zeitlich viel schneller aufzulösen. Die Serverless-Dienste wie z.B. AWS Lambda hingegen werden nur für die tatsächliche Nutzung abgerechnet, und können somit sekundenschnell auf Lastwechsel reagieren.
Lastschwankungen aufgrund wechselnder Popularität
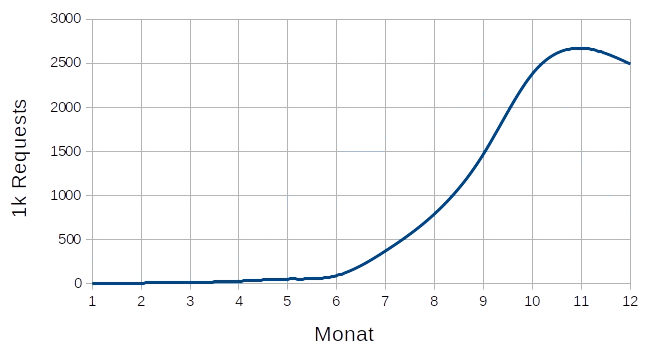 Diese meist langsamen und gleichmässigen Wechsel der Zugriffe können im Prinzip auch in normalen
Rechenzentren durch regelmässiges Austauschen der Hardware
ausgeglichen werden. Allerdings wird wegen abnehmender Last ein Hardwareverkäufer den nun zu
leistungsfähigen Server vermutlich nicht zurücknehmen.
Auch gemietete Server sind meist zeitlich an längere Perioden gebunden und somit nicht wirklich
geeignet, um an abnehmende Last zeitnah angepasst
werden zu können. Ebenfalls ist es natürlich so, dass die Granularität einer solchen Skalierung
relativ schlecht ist, da es sich aufgrund von Platz
und Anschlüssen nicht lohnt, mit kleinsten Servereinheiten zu arbeiten.
Diese meist langsamen und gleichmässigen Wechsel der Zugriffe können im Prinzip auch in normalen
Rechenzentren durch regelmässiges Austauschen der Hardware
ausgeglichen werden. Allerdings wird wegen abnehmender Last ein Hardwareverkäufer den nun zu
leistungsfähigen Server vermutlich nicht zurücknehmen.
Auch gemietete Server sind meist zeitlich an längere Perioden gebunden und somit nicht wirklich
geeignet, um an abnehmende Last zeitnah angepasst
werden zu können. Ebenfalls ist es natürlich so, dass die Granularität einer solchen Skalierung
relativ schlecht ist, da es sich aufgrund von Platz
und Anschlüssen nicht lohnt, mit kleinsten Servereinheiten zu arbeiten.
Auf AWS kann man langfristige Lastschwankungen sowohl mit virtuellen Instanzen, als auch Serverless sehr granular folgen. Im ersten Fall eignet sich dabei eine Kombination aus horizontaler und vertikaler Skalierung, damit man einerseits eine gute Granularität hinbekommt, und gleichzeitig mit Reserved Instances von grossen Kostenersparnissen profitieren kann.
Die Serverless-Dienste von Amazon könnten langfristige Lastbewegungen eigentlich auch gut abdecken, und können im Gegensatz zu der Lösung mit virtuellen Instanzen auch nahtlos bis auf 0 runterfahren, ohne ihre (Hoch-)Verfügbarkeit einzubüssen. Da die Grundkosten für Serverless-Dienste allerdings höher sind, lohnt sich deren Einsatz nicht um ausschliesslich langfristige Schwankungen abzudecken. Wenn man allerdings sowieso schon aus anderen Gründen auf Serveless setzt, dann muss man sich um langfristige Laständerungen auch keine Gedanken machen.
Kurzfristige Lastspitzen aufgrund spezieller Ereignisse
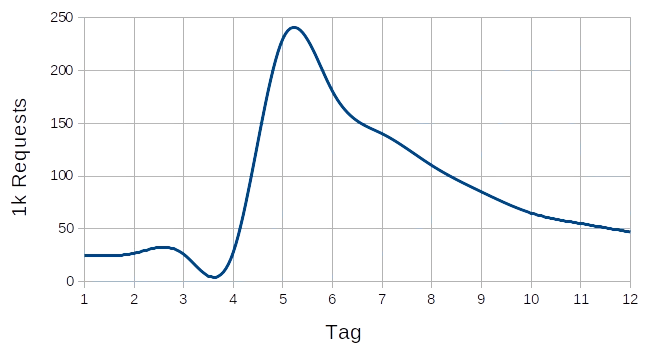 Wer schon etwas länger in der IT-Welt unterwegs ist, kann sich vielleicht noch an den Slashdot-Effekt erinnern. Heute müsste es wohl
eher Twitter-Effekt heissen.
Damit ist gemeint, dass die Last auf eine Webseite innerhalb kurzer Zeit um einen grossen Faktor
steigen kann, weil ein anderer populärer Dienst einen Link
dazu verbreitet hat. Eine kurzfristige Lastspitze kann auch durch die Effekte eigener
Marketingbemühungen oder externer Faktoren wie Black Friday usw.
entstehen. Webseiten, die nicht auf solche Lastspitzen vorbereitet sind, stellen dabei den Dienst
während der Dauer der Spitze oft nahezu vollständig ein,
was neben den finanziellen Ausfällen auch zu einem grossen Imageschaden führen kann.
Wer schon etwas länger in der IT-Welt unterwegs ist, kann sich vielleicht noch an den Slashdot-Effekt erinnern. Heute müsste es wohl
eher Twitter-Effekt heissen.
Damit ist gemeint, dass die Last auf eine Webseite innerhalb kurzer Zeit um einen grossen Faktor
steigen kann, weil ein anderer populärer Dienst einen Link
dazu verbreitet hat. Eine kurzfristige Lastspitze kann auch durch die Effekte eigener
Marketingbemühungen oder externer Faktoren wie Black Friday usw.
entstehen. Webseiten, die nicht auf solche Lastspitzen vorbereitet sind, stellen dabei den Dienst
während der Dauer der Spitze oft nahezu vollständig ein,
was neben den finanziellen Ausfällen auch zu einem grossen Imageschaden führen kann.
Je nach Grösse der Lastspitze kann es auch auf AWS mit einem einfachen Skalierungsplan eng werden. Es gibt nämlich standardmässig ein Limit für gleichzeitig laufende Instanzen pro Region (eigentlich ein vCPU Limit). Wenn man dieses Limit nicht im Vorfeld hat anheben lassen, kann es sein, dass der Slashdot-Effekt die skalierten Instanzen überlastet. Selbst wenn man dies gemacht hat, kann es sein, dass viele Anfragen nicht beantwortet werden können, denn es gibt beim Start einer neuen Instanz eine kurze Periode, während welcher sie hochfährt und vorbereitet wird, und noch keine Anfragen bedient werden. Ausserdem ist das Intervall, mit welchem Metriken, die für eine Skalierungsentscheidung verwendet werden können, mit einer Minute relativ lang. Wegen diesen Faktoren können auch mit dem besten auf EC2 Instanzen basierenden Skalierungsplan extreme Lastspitzen nicht vollständig abgedeckt werden.
Eine ganz auf Serverless-Dienste ausgerichtete Infrastruktur kommt auch mit sehr grossen Lastspitzen gut zurecht. Auch hier gibt es natürlich Verzögerungen, wenn skaliert werden muss, doch diese können viel kürzer gehalten werden, was bedeutet, dass eine Serverless Webapp viel schneller wachsen und schrumpfen kann, als jede andere hier beschriebene Lösung.
Ist es wirklich so einfach?
Dieser Artikel hat die Thematik auf einer stark vereinfachten Stufe betrachtet. In einem konkreten Fall gibt es natürlich noch einige weitere Faktoren zu berücksichtigen, welche die obigen Erkenntnisse völlig verändern können. Wenn eine Lastspitze z.B. fast ausschliesslich statische Ressourcen abfragt, kann bereits ein simples Setup mit einem CDN wie Cloudfront oder einem simplen HTTP Cache genügen, um sie abzufangen. Auch Memory-Caches wie Redis können die Ausgangslage schon wesentlich verändern. Ebenso wurden auf Containern basierte Infrastrukturen nicht eingeordnet. Diese sind im Rahmen dieses Artikels ungefähr mit einer Serverless Architektur gleichzusetzen, benötigen aber einen erheblich grösseren Konfigurations- und Administrationsaufwand.
Es gilt also auch im Umgang mit Lastschwankungen, dass es keine pfannenfertigen Patentlösungen gibt, und man jede IT Infrastruktur nur dann angemessen auf jede Lastsituation vorbereiten kann, wenn man eine an die individuellen Bedürfnisse und Gegebenheiten angepasste Lösung entwickelt.