Warum Serverless
Autor: Adrian Schweizer, Datum: 19. Juli 2022
Die hauptsächlichen Vorteile, die Serverless Webapps verglichen mit traditionellen Architekturen bieten, und in diesem Blog-Post beleuchtet werden, sind eingebaute Hochverfügbarkeit, automatische Elastizität und Kosten nach Verbrauch und nicht nach Kapazität.
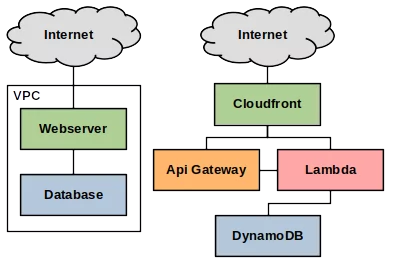 Um die drei Vorteile von Serverless Webapps hervorzuheben, vergleichen wir zwei funktional identische
Webapplikationen.
Die eine ist traditionell in einem VPC installiert und besteht aus einer EC2 Instanz, auf welcher der Webserver
läuft,
und einer weiteren EC2 Instanz, auf welcher eine Datenbank installiert ist (z.B. MongoDB). Die Serverless Webapp dagegen
besteht aus einer Cloudfront
Distribution, welche über AWS Lambda
das Frontend ausliefert (z.B. Remix) und über API
Gateway mit dem Backend kommuniziert.
Als Datenbank kommt DynamoDB zum
Einsatz. Weitere Dienste wie
S3 für statische Files oder EventBridge
um Teile der Applikation voneinander zu entkoppeln können ebenfalls eingesetzt werden.
Um die drei Vorteile von Serverless Webapps hervorzuheben, vergleichen wir zwei funktional identische
Webapplikationen.
Die eine ist traditionell in einem VPC installiert und besteht aus einer EC2 Instanz, auf welcher der Webserver
läuft,
und einer weiteren EC2 Instanz, auf welcher eine Datenbank installiert ist (z.B. MongoDB). Die Serverless Webapp dagegen
besteht aus einer Cloudfront
Distribution, welche über AWS Lambda
das Frontend ausliefert (z.B. Remix) und über API
Gateway mit dem Backend kommuniziert.
Als Datenbank kommt DynamoDB zum
Einsatz. Weitere Dienste wie
S3 für statische Files oder EventBridge
um Teile der Applikation voneinander zu entkoppeln können ebenfalls eingesetzt werden.
Eingebaute Hochverfügbarkeit
Die traditionelle Architektur hat mehrere Problemstellen, bei denen ein Ausfall einer einzelnen Komponente das gesamte System lahmlegt. Wenn z.B. der Webserver abstürzt, werden keine Kundenanfragen mehr bedient. Um dem zu begegnen, müsste man einen zweiten Webserver laufen lassen und dann z.B. einen Elastic Load Balancer vorschalten. Selbst dann wäre man noch nicht gegen den Ausfall des gesamten Rechenzentrums, in dem die Server sich befinden, gewappnet. Dazu müsste man den zweiten Webserver explizit in eine zweite Availability Zone auslagern. Dies bringt dann jedoch die Problematik der Storage-Replikation ins Spiel, da nun beide Server in verschiedenen Rechenzentren stehen. Dieselben Fragestellungen kommen nochmals bei der Datenbank auf.
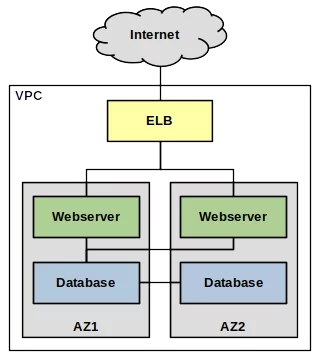 Eine Webapp, die nach Serverless-Prinzipien aufgebaut ist, hat Hochverfügbarkeit bereits eingebaut,
da alle Dienste,
die sie benutzt, von Amazon bereits mit Hochverfügbarkeit betrieben werden (z.B. AWS Lambda). Es gibt keine zentralen
Ausfallpunkte
und als Betreiber der Webapp muss man sich in dieser Hinsicht keine weiteren Gedanken zur
Infrastruktur machen.
Eine Webapp, die nach Serverless-Prinzipien aufgebaut ist, hat Hochverfügbarkeit bereits eingebaut,
da alle Dienste,
die sie benutzt, von Amazon bereits mit Hochverfügbarkeit betrieben werden (z.B. AWS Lambda). Es gibt keine zentralen
Ausfallpunkte
und als Betreiber der Webapp muss man sich in dieser Hinsicht keine weiteren Gedanken zur
Infrastruktur machen.
Automatische Elastizität
Damit die traditionelle Architektur der schwankenden Last der Zugriffe gewachsen ist, muss entweder genügend Kapazität für die Spitze bereitgestellt werden, oder es muss manuell ein Autoscaling Setup eingerichtet werden. Hier gilt es, den Webserver- und Datenbankteil separat zu skalieren und dabei trotzdem aufeinander abzustimmen, damit keiner den anderen ausbremst. Bei fallender Last muss zudem ein spezielles Augenmerk darauf gelegt werden, dass Kapazität auch wieder abgebaut wird. Natürlich sollte auch in diesem Setup die Hochverfügbarkeit stets gewährleistet sein.
Bei der Serverless Webapp ist die Elastizität bereits in den einzelnen Diensten eingebaut und sie kann deshalb ohne weitere Konfiguration dynamisch auf steigende und fallende Last reagieren.
Kosten nach Verbrauch
Üblicherweise kommen virtuelle Maschinen bei der traditionellen Architektur zum Einsatz, oder die Software wird allenfalls in isolierte Container gepackt, die um eine gewisse Grundlast abdecken zu können, ständig laufen müssen. Man bezahlt hier also für bereitgestellte Kapazität, egal, ob sie genutzt wird, oder nicht. Dank Autoscaling kann man diese Kosten relativ tief halten, aber gewisse Verluste aufgrund mangelnder Granularität und keiner Möglichkeit auf 0 zu skalieren ohne Dienstausfall bleiben trotzdem eine Realität dieses Modells.
Eine Serverless Webapp kann komplett mit Diensten umgesetzt werden, welche nach Verbrauch abgerechnet werden. Jeder Request und jede Belegung von Speicher wird granular abgerechnet, und die Infrastrukturkosten wachsen so dynamisch mit der Last mit. Wenn keine Last auf den Systemen ist, entstehen auch keine Kosten. Dank einem monatlich wiederkehrenden Free Tier für viele Dienste (z.B. erste Million Requests pro Monat auf AWS Lambda) können kleinere Applikationen fast vollständig kostenlos betrieben werden. Erst wenn die Last über die monatliche Freigrenze steigt, wird der Verbrauch abgerechnet.
Warum doch nicht Serverless
Natürlich ist Serverless kein Allheilmittel und bringt auch wesentliche Nachteile mit sich. So gibt es auf AWS Lambda sowohl ein Memory- als auch ein Zeitlimit für jeden einzelnen Request. Oder DynamoDB eignet sich nicht für im Voraus nicht bekannte Abfragen, wie sie für analytische Zwecke oft benötigt werden. Ebenso kann es sein, dass eine Serverless Webapp höhere Kosten generiert als eine traditionelle Lösung, nämlich dann, wenn die Last nur leicht schwankt, und man so die Kapazität nahezu perfekt dafür auslegen kann. So kann man anschliessend mit den Reserved Instance Preismodellen, bei welchen man sich langfristig für eine gewisse Kapazität entscheidet, von grossen Preisnachlässen profitieren.
Ebenso macht es unter Umständen wenig Sinn, eine bereits bestehende traditionelle Applikation auf Serverless umzubauen, wenn sie sowieso bald abgeschaltet werden soll, oder kein Entwicklungsbudget für den Umbau zur Verfügung steht. Ausserdem benötigt die Entwicklung einer Serverless Webapp spezielles Knowhow, welches im Entwicklungsteam evtl. nicht vorhanden ist.